Additional considerations for research pipelines¶
This is continuation of Advanced Kubernetes Practical. There are additional considerations that we feel strongly about. It is a bit tricky to make practical exercises so we just share our opinions as reading materials for now.
- Reading 1: Bringing compute close to data
- Reading 2: Resource consumption
- Reading 3: Docker builds
- Reading 4: CI/CD toolchain
Reading 1: Bringing compute close to data¶
In the era of cloud computing, compute is not the center of the universe. Data is. Always try to bring compute to data, instead of data to compute for big data problems. The key is to make the compute highly portable.
In this project, we have to investigate the possibility to run Freebayes / Samtools on GKE due to the computing resource allocated to worker nodes. This means that we no longer have “local” access to the data storage within EBI. There are many solutions to access data remotely, which also means that there is no single solution solving most of the problems without creating their own share of issues.
We are using a combination of wget, gzip and samtools. Different tools and strategies may be necessary to reduce the overall cost of network, cpu, memory, storage, and computing and development time. We are trying to find the best solution. Please do shed some light to help us if you have any thoughts.
Reading 2: Resource consumption¶
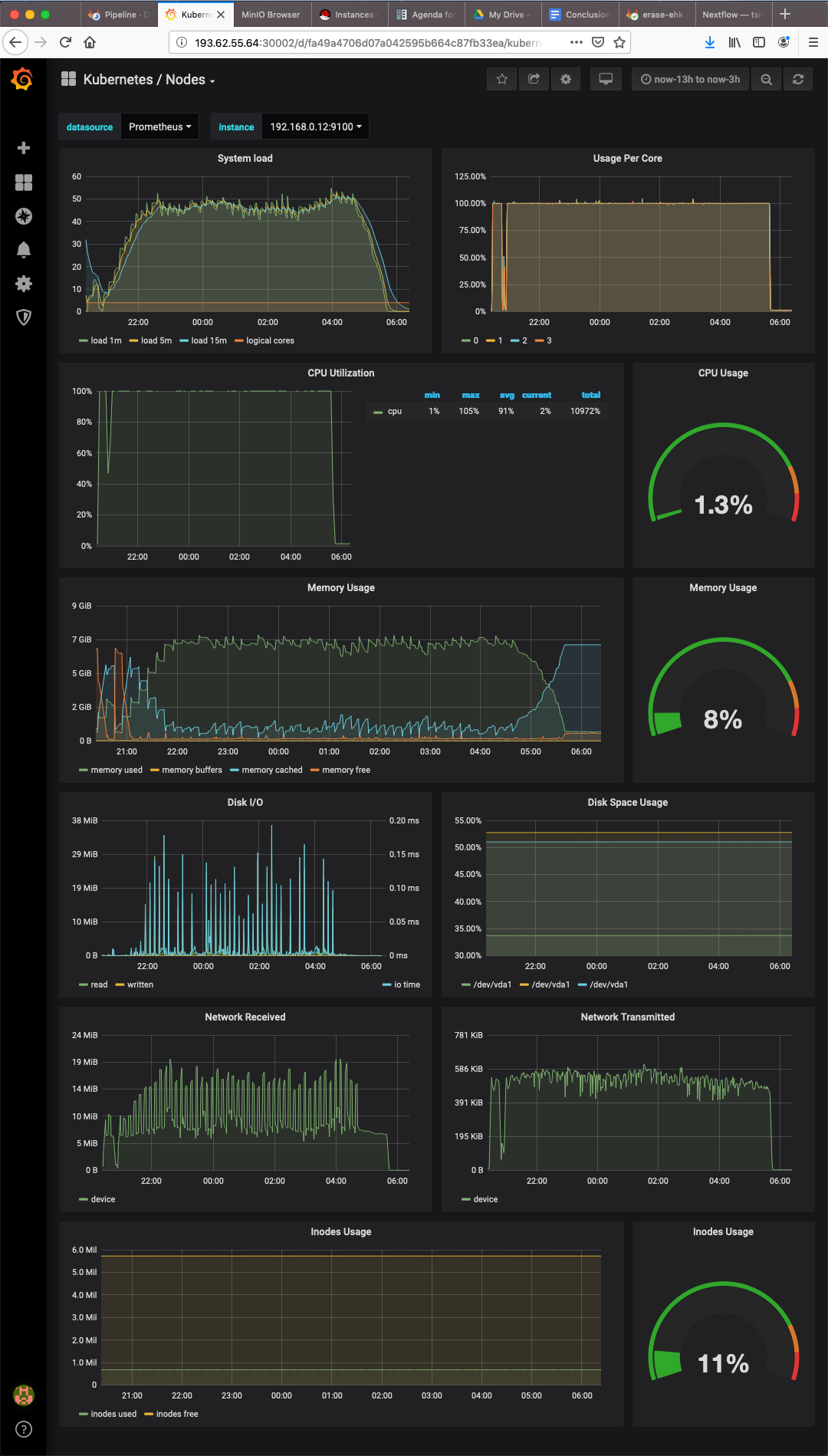
It is of paramount importance to monitor resource consumption to understand where the bottlenecks are. Prometheus & Grafana provide a simple monitoring tool but useful enough to view resource dynamics. The screenshot below shows an attempt to scale up Kubernetes pods to call variants in all 1000 genomes.
- CPU was maxed out almost immediately.
- Memory consumption kept increasing over about a hour and a half.
- Disk IO, network IO, disk space and Inode usage were all OK.
- The system failed after runing for about 8 hours.
- The dashboards for other worker nodes showed the same behaviour.
There were seemingly random SIGABRT errors on the SSH client after a while. There may not be enough CPU to handle scheduled jobs. There may be severe memory leaks by Freebayes, which eventually chocked up the pipeline. We can take the following actions:
- Reducing the batch size so that there are less jobs waiting for CPU cycles
- Adding more CPUs to the existing nodes and / or more nodes with larger number of CPUs
- Using more sophisticated job scheduler instead of Bash script + Kubernetes
We would not know what to do otherwise. A resource monitor is useful for development, test and production.
Reading 3: Docker builds¶
There are two tools in the pipeline: Samtools and Freebayes. we have containerised the tools and wrapper / driver scripts. Here are some best practices to follow:
- Creating two separate containers to manage them separately at runtime.
- Starting with minimal base image, for example debian:buster-slim instead of ubuntu:bionic for example.
- Creating CI/CD toolchain to buiid Docker images to avoid doing repetitive work.
- Downloading binaries from trusted source only.
- Building from the source if only necessary.
- Including wrapper / driver scripts in the container for good encapsulation.
- Minimising the number of layers if possible.
- Ording layers according to the likelihood of changes.
Here an example of Docker files:
The build jobs can be part of a larger toolchain to create Kubernetes cluster, to deploy and to run workload. This gives you better control and nicer integration. Docker hub can build images when integrated with a source control repository directly. But it provdes limited resources with less control. There is private repository for Docker images at EBI. My personal preference is to push the image built on GitLab to Docker Hub. The build process can take the following steps:
- git clone ${CI_GIT_URL}
- cd ${CI_BUILD_CONTEXT}
- docker login -u "${CI_REGISTRY_USER}" -p "${CI_REGISTRY_PASSWORD}" ${CI_REGISTRY}
- docker build -f ${CI_DOCKER_FILE} -t ${CI_SOURCE_IMAGE} ${CI_BUILD_CONTEXT} | tee ${ARTIFACT_DIR}/build.log
- docker tag ${CI_SOURCE_IMAGE} ${CI_REGISTRY_IMAGE}:${CI_COMMIT_REF_SLUG}
- docker push ${CI_REGISTRY_IMAGE}:${CI_COMMIT_REF_SLUG} | tee ${ARTIFACT_DIR}/push.log
- docker logout
You can simply perform the seven steps to build an image on a standard GitLab runner with DIND enabled. Here is a link to the images created with this process https://hub.docker.com/?namespace=davidyuyuan.
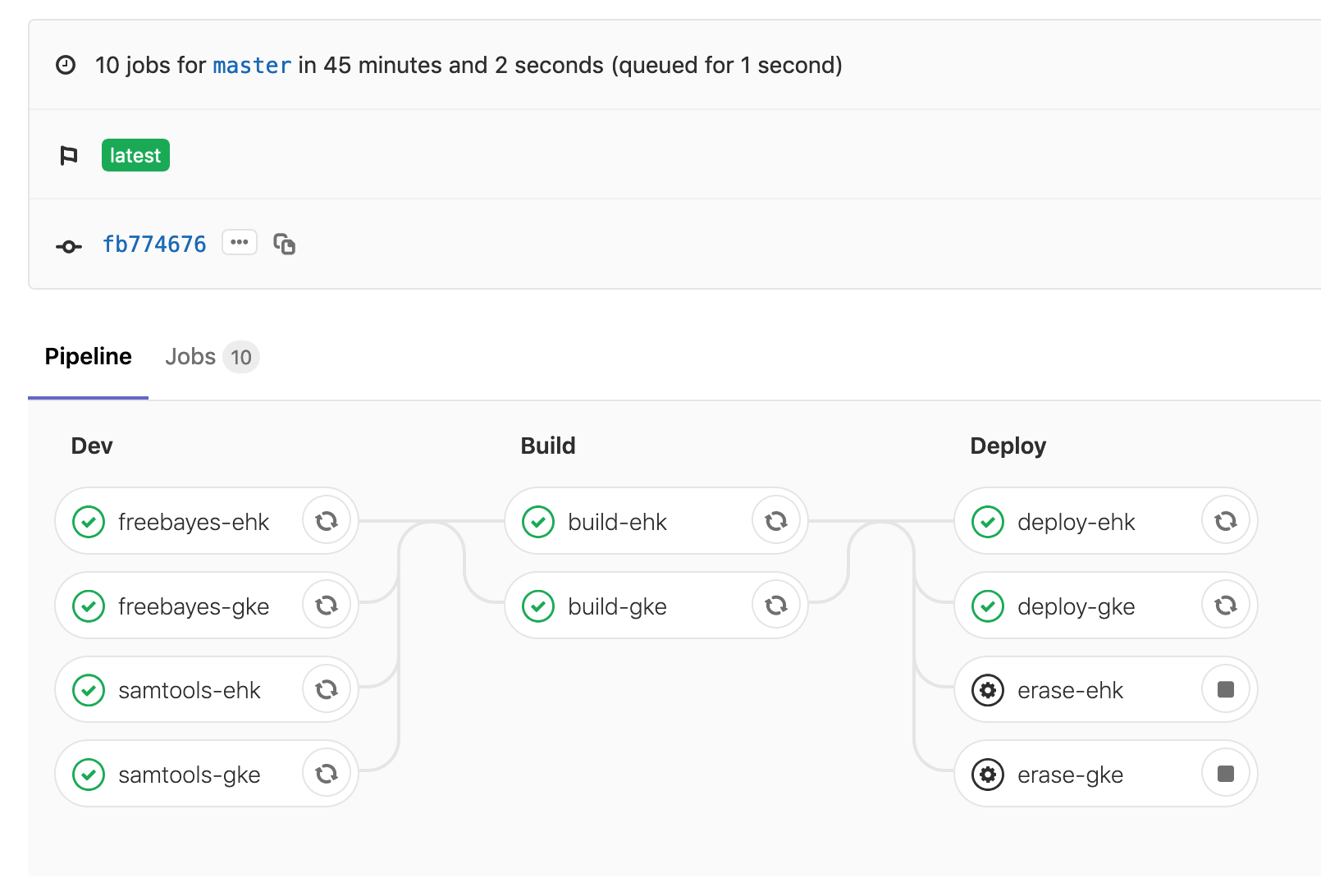
Reading 4: CI/CD toolchain¶
In addition to creating Docker images, many other jobs are needed in order to assemble the pipeline to produce VCFs for 1000g. Here are the major tasks:
- Building Docker images for target clouds
- Creating / configuring Kubernetes cluster on OpenStack (RKE) or Google (GKE)
- Deploying pipeline into the environments and performing smoke-test
- Clean up Kubernetes clusters when finished
The CI/CD toolchain below automates all the jobs. It improves the DevOps efficiency significantly. Always creating CI/CD toolchain. You will see immediate savings. Here are the links to the CI files:
- https://gitlab.ebi.ac.uk/davidyuan/adv-k8s/blob/master/.gitlab-ci.yml
- https://gitlab.ebi.ac.uk/davidyuan/adv-k8s/blob/master/gcp/.gitlab-ci.yml
- https://gitlab.ebi.ac.uk/davidyuan/adv-k8s/blob/master/osk/.gitlab-ci.yml